
VGGNet
VGGNet
VGGNet(Visual Geometry Group Network)是一种深度卷积神经网络架构,由牛津大学视觉几何组(Visual Geometry Group)的研究团队开发。VGGNet在2014年被提出,并在当年的ImageNet图像识别挑战中取得了优异的成绩。
优点
1.网络结构简单规整:VGGNet采用了相同大小的卷积核和池化核,并且每个卷积层后面都紧跟着一个池化层,使得整个网络结构变得规整而易于理解。这种结构设计简化了网络的复杂性,使得网络更容易实现和调整。
2.深度网络:VGGNet通过增加网络的深度来提高模型的表达能力。相比于之前的网络结构,VGGNet使用了更多的卷积层,包含16层或19层,使得网络能够更好地捕捉图像中的细节和复杂特征。
3.小尺寸卷积核:VGGNet使用了小尺寸的卷积核(3x3),这种设计可以有效地减少网络的参数数量。通过堆叠多个小尺寸的卷积核,VGGNet可以捕获更丰富的特征信息,并减少过拟合的风险。
4.通用性和迁移学习:VGGNet的网络结构通用性强,可以应用于不同的计算机视觉任务。由于VGGNet在大规模图像数据集上进行了预训练,因此可以将其作为迁移学习的基础模型,通过微调或特征提取来解决其他任务,如目标检测和图像分割。
舍弃LRN

有趣的是,论文中通过实验证明使用LRN并不会减少误差。
缺点
1.大量参数和计算复杂度:VGGNet的网络结构非常深,具有较多的卷积层和全连接层。这导致了大量的参数需要学习,并且网络的计算复杂度较高。这使得训练和推理过程需要更多的计算资源和时间。全连接层第一层有7×7×512×4096个参数,总共有一亿多个。
2.内存消耗较大:由于VGGNet具有大量的参数,它需要较大的内存空间来存储模型参数和中间特征图。这对于具有受限内存的设备或系统来说可能是一个挑战。且内存占用主要是第一个卷积层,224×224×64。
模型结构
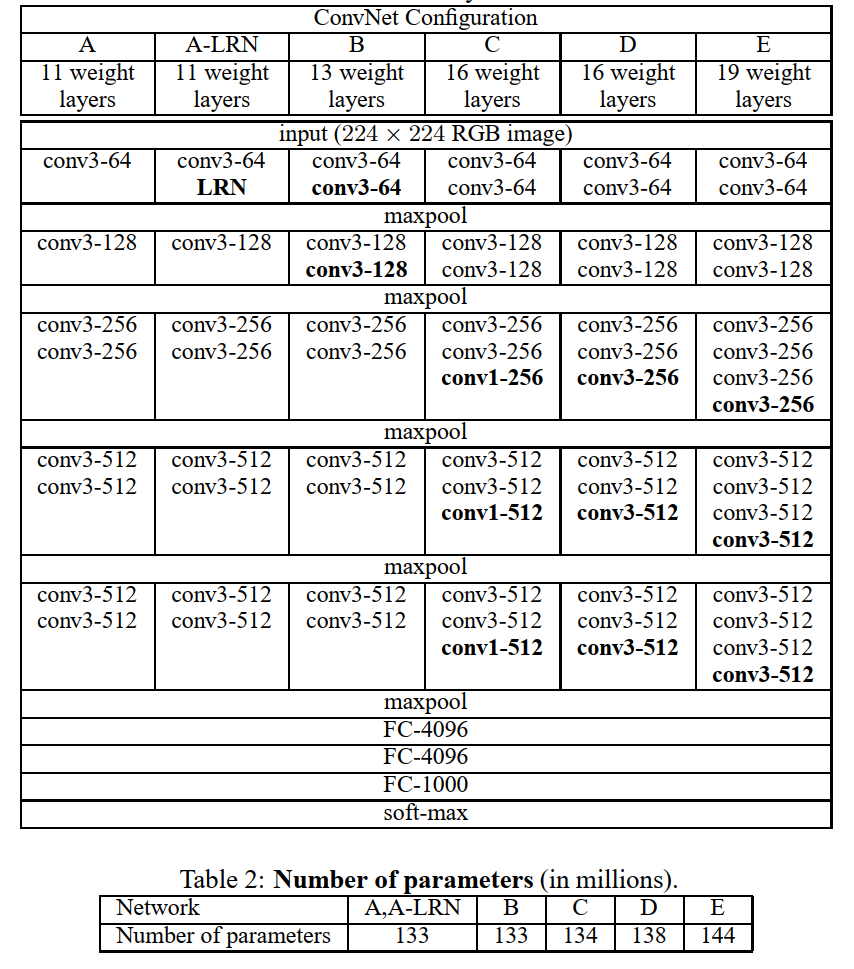
1.输入层:VGGNet的输入层接受原始图像作为输入。通常情况下,输入图像的大小为224x224像素,但可以根据需要进行调整。
2.卷积层:VGGNet使用多个连续的卷积层,每个卷积层都使用相同数量的滤波器(filter)。滤波器的大小固定为3x3像素。通过使用小尺寸的滤波器,VGGNet可以捕捉到更细节和局部的图像特征。卷积层之间使用ReLU(Rectified Linear Unit)作为激活函数,用于引入非线性。
3.池化层:在每个卷积层之后,VGGNet使用池化层来减小特征图的空间尺寸并降低计算量。VGGNet采用的是最大池化(Max Pooling),池化层的大小为2x2像素,步幅(stride)为2。这意味着特征图的尺寸被减半。
4.全连接层:在经过多次卷积和池化后,VGGNet将特征图展平为一维向量,并通过全连接层将其映射到类别概率。VGGNet使用了一到多个全连接层,每个全连接层都包含多个神经元。全连接层的输出通过softmax函数进行归一化,得到每个类别的概率分布。
5.分类器:VGGNet的最后一层是分类器,它采用了softmax激活函数,将全连接层的输出映射为每个类别的概率。根据具体的任务需求,分类器的输出层的神经元数量等于类别的数量。
代码
import torch
import torch.nn as nn
# VGG网络的卷积层配置
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 定义VGG网络
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, num_classes) # num_classes是分类任务的类别数量
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _make_layers(self, cfg):
layers = []
in_channels = 3 # 输入图像通道数
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)